2016年末,Facebook上的假新闻帮助特朗普胜选的消息,将这家社交网站推到一个尴尬的境地,迫使它上线一个“争议(Disputed)标签”功能,用来标记被认定为不准确的新闻。
作为一家面向全球的社交平台,Facebook当前月活跃用户数达已达18.6亿人,其中包含各个年龄阶段的用户,这些用户每天都产生大量信息。为了保证用户体验,促进平台良性发展,Facebook通过技术手段和人工手段相结合的方式,针对内容本身和用户帐号进行识别,来实现反垃圾信息的目标。垃圾信息在不断变化,Facebook的反垃圾策略和技术系统也在不断升级。

Facebook上的网络钓鱼攻击,2011年
Facebook反垃圾策略
制定反垃圾策略首先需要明确的是垃圾信息的定义。对于Facebook而言,无论恶意的广告、病毒、网络钓鱼,无聊/不受欢迎的骚扰,惊悚、恶作剧类的图文、视频,还是前文提到的虚假新闻,无论私信形式还是公开信息,都会影响网站的正常运营,可能是让用户不高兴,可能是让一些美国政治力量不高兴,这些都属于垃圾信息的范畴。
从网站上每秒钟产生的海量信息中找出垃圾信息并实时过滤,这是最直接的办法,然而根据Facebook的活跃用户数,从需要的资源和效率来看,这种方法可能不是最优解,况且垃圾信息也会根据过滤规则不断升级,因而找出垃圾信息的难以改变的特征才是将其扼杀的最好依据,这正是Facebook反垃圾工作的核心。Facebook组建了Site Integrity团队专门负责这项工作。
Facebook反垃圾的一个重要途径,就是识别和处理一些可疑帐号。Facebook认为,泄漏的(被钓鱼、中木马等)、伪造的(马甲帐号、垃圾帐号)以及滥用功能的(骚扰、营销)帐号,产生垃圾信息的三大根源。
找到可疑帐号的一个方法,是通过异常行为检测,比如一个人发的同样类型评论非常多,所有评论里都包含一个相似链接,这就非常有问题。一般人不会在不同人的主页上发表一样的评论,这就是一种异常行为。Facebook网站上积累了大量的正常行为模式和异常行为模式,可以用于机器学习。
作为一个社交平台,Facebook还充分发挥了人的力量,用户举报在垃圾信息的识别中占据了很重要的位置。用户举报也是缩短垃圾信息影响时间的一种方式 – 为了达成反垃圾策略的实时性、有效性,Facebook反垃圾系统的设计会采用各种机制来优化响应时间,并在策略制定时注意保护规则难以被攻击者破解。
Immune系统:基于核心特征的技术对抗
2011 年,Facebook 发表了一篇题为《FacebookImmune System》的论文,整体介绍了他们与垃圾信息之间的技术对抗。Immune系统的一个重要能力,是对垃圾信息的核心特征的识别,包括能够迅速识别新特征,并支持在线加入新特征、新模型以实现实时的反垃圾。
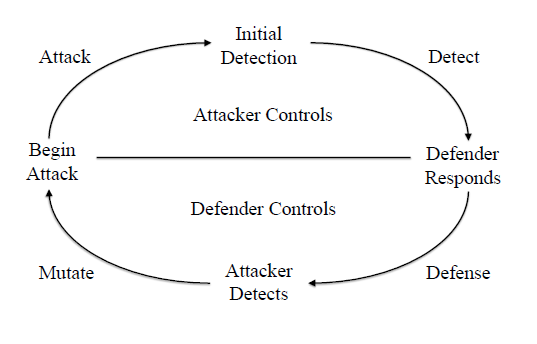
上图为Facebook与垃圾信息的对抗流程,包括攻击、检测、防御、变异四个环节,又可以分为攻击者控制和防御者控制两大阶段。在攻击者控制阶段,系统还没有响应能力,攻击者可以发布大量的垃圾信息,受攻击对象都会受到垃圾信息的影响;在防御者控制阶段,垃圾信息才会受到控制。Immune系统要做的,是尽量缩短攻击者控制阶段的时间,延长防御者控制阶段的时间。变异环节可能时间很短,Facebook要在对抗中做到快速响应。
实现快速响应有两个关键点:其一,所有的升级都是在线的,分类器服务和代表最新攻击的特征数据的提供,都不能是通过线下或者需要重新启动;其二,要以攻击者难以检测和变更的特征为目标。
Facebook为Immune系统的设计归纳的设计原则如下:
· 快速检测与响应;
· 包含能够支持各种功能的可进化的接口;
· 聊天、消息、信息墙(wallposts)、公共讨论和朋友请求等不同渠道之间的信号可以共享;
· 可以实时分类。
基于上述思想,Immune 系统设计架构图如下:
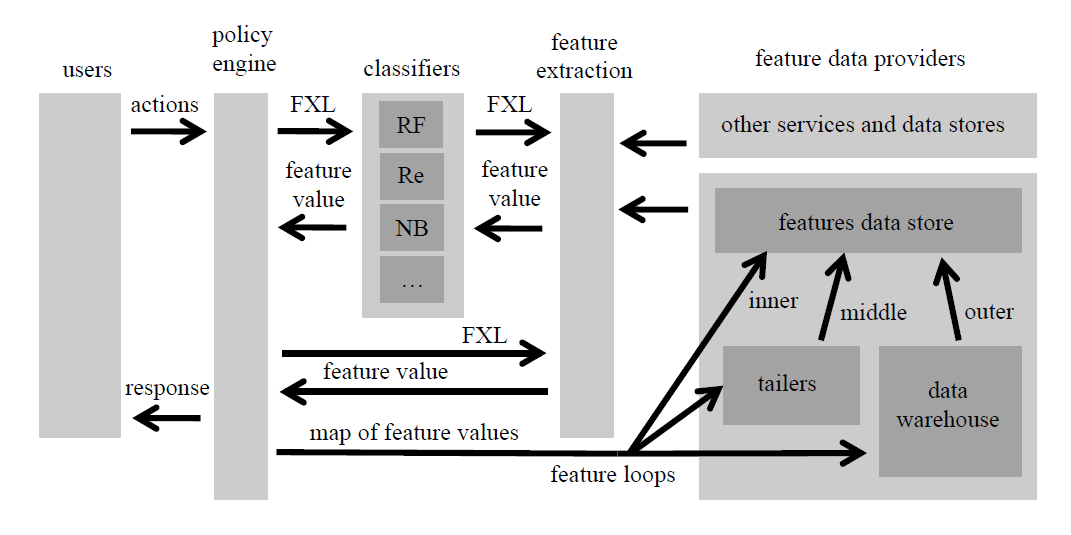
Facebook Immune系统架构图
Immune的主要组件包括:
• 分类器服务:分类器服务是一类接口,它们与抽象分类器接口之间建立网络联接。它们之间通过不同的机器学习算法,使用标准的面向对象的方法来实现的。实现的算法包括随机森林、SVM、逻辑回归、Boosting等。分类器服务始终在线,并且被设计为从不重新启动。
• 特征提取语言(FXL):FXL(FeatureExtraction Language)是用于表达特征和规则的动态执行语言。FXL检查特征表达式,然后在线加载到分类器服务和特征追踪器中,无需重新启动服务。
• 动态模型加载:模型建立在特征之上,而这些特征都是基本的FXL表达式或其派生的表达式。同样地,模型在线加载到分类器服务,分类器服务或特征追踪器无需重新启动,并且许多分类器实现支持在线训练。
• 策略引擎:策略引擎将分类和特征结合起来表达业务逻辑和业务策略,并评估分类器的性能。策略是布尔值,由FXL表达式触发响应,在机器学习得到的分类和特征数据提供者之上执行。响应是系统操作,包括多种类型,例如阻止操作、要求身份验证质询和禁用帐号等。
• 特征回路(Floops):分类在特征提取期间生成各种信息和关联,Floops接收这些数据,将其聚合,并将其作为特征提供给分类器。Floops还包含用户反馈、来自爬虫程序的数据以及来自数据仓库的查询数据。
Sigma系统:编写策略手段升级
Facebook的反垃圾技术也在不断的对抗中迭代。Facebook用于垃圾信息过滤和清理的规则引擎演进为Sigma系统,部署于2000多台服务器之上。该系统将规则和机器算法相结合,判断所有用户的评论、链接、朋友请求等行为是否正常,日均处理信息数量达百亿级。
机器学习的一端,样本主要来自于用户行为,Sigma根据历史数据训练模型,预测某个行为/信息是否有问题,将有问题的行为/信息拦截或者删除。以朋友请求为例,Sigma有多重判断依据:第一,如果某个帐号之前发送的朋友请求都被拒绝,那么接下来他被拒绝的概率就非常高;第二,如果发出请求的帐号和请求的对象没有任何共同好友,那么请求不合理的概率也很高。策略也包含了处理方式,例如,对于非正常请求概率比较高的,让发送请求方进行手机短信验证,或者其他方式认证。
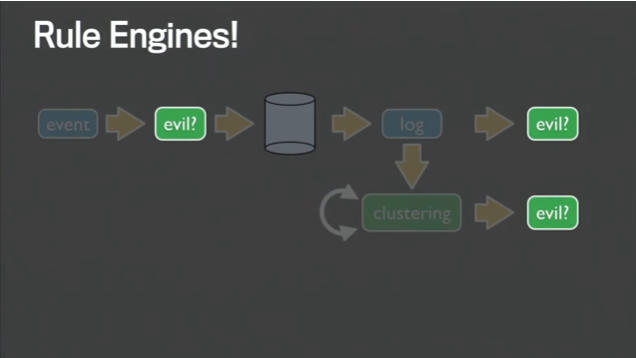
Facebook反垃圾规则引擎流程图
Sigma系统中,用于编写策略的语言,已经从之前的FXL切换为Haskell。Facebook认为,随着策略的扩展和策略复杂度的增加,FXL已经不能很好地表达这些策略了- FXL缺乏合适的抽象,比如用户定义的数据类型和模块,并且基于解释器(Interpreter)的实现,性能慢于公司的需求,因而Facebook需要性能和表达能力更为成熟的编程语言。而Haskell是纯函数式强类型语言,能够确保策略不会发生意外的相互影响,同时Haskell具有自动批处理和并发数据获取、分钟级推送代码变更到生产环境(快速应用新策略)、性能和支持交互式开发(策略开发者能够马上看到结果)等优势。

规则引擎升级的设计需求
使用Haskell以后,Sigma系统每秒能够处理超过一百万个请求。这对Facebook及时部署新的反垃圾策略应对新出现的恶意行为很重要。
人的力量
Facebook此前也投入了专门负责内容过滤的团队,让他们不间断地监测新上传的内容,及时删除其中的一些垃圾信息,这些人主要来自外包公司。外界并不知道该团队目前的规模,然而Facebook重视用户举报是确凿的。通过举报、删除等反馈通道的建立,来缩短垃圾信息影响用户的时间。同时,这些行为也会为机器学习提供新的样本。
针对虚假新闻,Facebook已经推出工具,让每位用户都能便捷地给可疑内容打上“争议”标签,然后由真实性核查组织如Politifact、Snopes.com独立审查这些消息,根据结果决定保留还是去除“争议”标签。然而这个流程稍显冗长,给虚假新闻留下了一定的传播时间。除此之外,Facebook还在虚假新闻的治理方面投入专人,公司已经发出招聘公告,寻求一位拥有20年以上经验的新闻合作负责人,专门负责提升网站上的新闻质量。
Facebook采用了新闻流排序算法,通过机器学习(根据点赞、评论、分享等行为)预测用户对内容感兴趣的程度,决定其排序的权重,这在某种意义上说也是反垃圾,然而目前还没有Facebook用排序算法影响虚假新闻的消息,这与Facebook对虚假新闻的态度有关:让用户和第三方机构来甄别,不会官方标明某条消息的真伪。
人力的方式,对于Facebook而言意味着很大的人力成本,同时对于审核人员的身体健康与心理素质也是一种考验。曾有外媒报道称,Facebook审查员工通常不到半年就离职。那么Facebook不断研发新的技术手段来提升反垃圾能力的动因就不难理解了。然而由于网站影响正常运营的垃圾信息日益复杂性,在这些垃圾信息消失之前,系统无法一劳永逸,技术对抗不会有终点,故而Facebook需要不断研发新的反垃圾技术,也需要人工来升级规则并提供样本优化系统的规则引擎。
文章来源:
①facebook论文:Facebook Immune System
作者:Tao Stein Erdong Chen Karan Mangla
②Fighting spam with Haskell
作者:Simon Marlow
翻译:网易易盾